技术领域
本发明涉及视频监控技术领域,尤其涉及一种基于视频跟踪的多目标车辆轨迹识别方法。
背景技术
随着交通设施的不断完善和人民生活水平的提高,道路上的车辆越来越多,交通安全问题也随之而来。在众多交通信息来源中,基于监控摄像头的视频数据具有不间断性、直观性、可靠性高等特点,因此基于监控视频进行车辆轨迹识别的方法是判断车辆行驶的动态过程中是否规范的重要手段之一。此外,车辆轨迹识别在当今已被应用在其他领域和行业中,例如汽车辅助驾驶系统中,在能见度低等恶劣环境下,通过车辆轨迹识别可以对驾驶人员进行提醒,保障行车安全。
目前,对于多目标车辆轨迹的识别技术主要可以分为两类,一是传统方法,即采用背景差分法、帧间差分法、光流法等方法提取运动目标,然后通过匹配算法和分类算法实现车辆的连续跟踪;二是基于卷积神经网络的深度学习方法。传统方法部署方便,消耗资源少,但是受限于先验知识,跟踪的稳定性差而且准确率不高;深度学习方法具有极高的准确性,但是计算量及其庞大,实时性不高。
发明内容
本发明要解决的技术问题是针对上述现有技术的不足,提供一种基于视频跟踪的多目标车辆轨迹识别方法,该方法不仅解决了多目标的车辆轨迹提取精度问题,而且具备很好的实时性,解决了现有基于深度学习方法的车辆轨迹提取精度和速度有限问题。
为解决上述技术问题,本发明所采取的技术方案是:
本发明提供一种基于视频跟踪的多目标车辆轨迹识别方法,包括如下步骤:
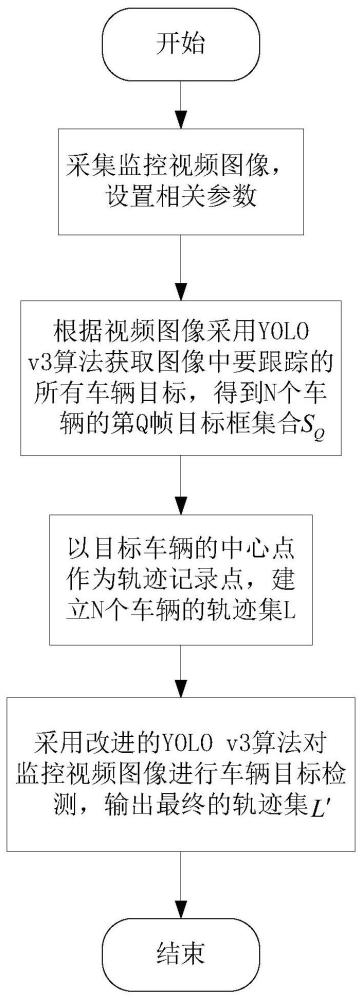
步骤1:采集监控视频图像,设置相关参数,所述相关参数包括改进的YOLO v3算法参数初始化、置信度阈值设定;
步骤2:根据视频图像采用YOLO v3算法获取图像中要跟踪的所有车辆目标,将检测到的N个车辆作为跟踪目标,得到N个车辆的第Q帧目标框集合SQ,并以目标车辆的中心点作为轨迹记录点,建立N个车辆的轨迹集L={L1,L2,L3,…,LN},其中LN代表目标车辆N的轨迹集合;
步骤3:启动跟踪;根据目标框集合SQ和Q+1帧的视频图像采用改进的YOLO v3算法进行车辆目标检测得到N个车辆Q+1帧的目标框集合SQ+1,重复本步骤,直至将采集的监控视频图像全部检测完毕,输出最终的轨迹集L′;
所述改进的YOLO v3算法为将输入图像划分为网格,利用KCF跟踪算法对当前帧进行处理,预测下一帧中车辆的位置,在下一帧中对预测位置中的网格进行检测,不再对所有网格进行检测;设定设计车辆检测专属的anchor的窗口尺寸和YOLO v3算法损失函数,然后采用YOLO v3算法获取目标框集合,得到目标车辆的轨迹集。
所述步骤2还包括如下步骤:
步骤2.1:网格划分;根据YOLO v3算法将输入图像进行网格划分,划分成S×S个网格;
步骤2.2:确定搜索区域;对帧数Q的视频图像进行全帧检测,搜索区域为视频图像中划分的所有网格;
步骤2.3:候选框预测:结合视频监控下的车辆特征设计一套车辆检测专属的anchor的窗口尺寸,即采用定制的五种长宽比和三种缩放比例的anchor,对步骤2.2中的搜索区域采用多尺度特征图方法进行候选框预测,每个网格会产生15个候选框,得到N个车辆的候选框集合PQ;
步骤2.4:多目标车辆区分,得到N个车辆的目标框集合SQ;采用非极大值抑制的方法对候选框集合内的所有候选框进行处理,从所有候选框中得到当前帧图像中所有车辆的唯一边界框;
步骤2.5:输出目标框集合SQ,SQ中每个车辆用唯一的边界框表示;该边界框由具有6维的向量表示,即(tx,ty,tw,th,tcon,ttra),其中tx、ty为边界框的左上点坐标、tw为边界框的长,th为边界框的宽,tcon为该边界框对应的置信度,ttra为边界框在跟踪区域中的置信度,且ttra=0,其中tcon的计算公式为其中,BBpre表示各个车辆对应目标框集合SQ中的边界框,BBtru表示各个车辆的真实边界框,area是对面积的求值;
步骤2.6:根据目标框集合SQ得到所有目标车辆的中心点,并以中心点作为轨迹记录点,建立N个车辆的轨迹集L={L1,L2,L3,…,LN}。
所述步骤3的具体步骤如下:
步骤3.1:基于第Q帧图像中N个车辆的目标框集合SQ,利用KCF跟踪方法计算在Q+1帧中原Q帧中N个车辆的响应值,并将Q+1帧中每个车辆对应的响应值大的前五名保存到样本序列CQ+1={c1,c2,…,ca,…,cN}中,其中代表第a辆车的响应值集合,并将各车辆的最大响应值对应的图像区域添加到预测区域集合KQ+1;
步骤3.2:置信度判断:分别计算当前帧中预测区域集合KQ+1与前一帧中目标框集合SQ各车辆预测框的IOU值,并将其作为置信度,得出置信度集合M=[m1,m2…mN],计算公式为ma的值范围为[0,1],其中,area表示各预测框的面积,sa代表第a辆车在Q帧时的目标框,ka代表第a辆车在Q+1帧时的预测区域,对置信度集合M中的元素分别判断其是否大于置信度阈值,若是,则认为是有效跟踪,则将预测区域储存至预测框集合K′Q+1中,执行步骤3.4;若否,则认为是无效跟踪,则获取所有无效跟踪的目标车辆以及目标车辆相对应的响应值集合,分别将响应值集合内的响应值依次作为当前帧的最大响应值,即预测区域,再进行置信度判断,若为有效跟踪,则将该预测区域储存至预测框集合K′Q+1中,执行步骤3.3;若目标车辆均为无效检测则认为车辆消失在监控视频中,则执行步骤3.4;
步骤3.3:判断预测框集合K′Q+1内的预测框数量是否为N个,若否,则删除预测框集合K′Q+1,执行步骤3.4,若是,则执行步骤3.5;
步骤3.4:根据Q+1帧的视频图像采用YOLO v3算法获取图像中要跟踪的N个目标车辆,得到N个车辆的第Q+1帧目标框集合SQ+1,执行步骤3.6;
步骤3.5:将预测框集合K′Q+1作为搜索区域,采用YOLO v3算法进行目标车辆检测,得到第Q+1帧的目标框集合SQ+1;
步骤3.6:轨迹获取与记录:计算得到的当前帧中所有车辆的中心点,并将各车辆的最新位置更新到轨迹集L={L1,L2,L3,…,LN}中;
步骤3.7:令Q=Q+1,执行步骤3.1;直至将采集的监控视频图像全部检测完毕,输出最终的轨迹集L′。
所述步骤3.1还包括如下步骤:
步骤3.1.1:获取候选样本集合:每次跟踪的基样本图像均由步骤2中检测出的多目标车辆的初始化状态确定,通过循环移位矩阵X完成密集采样以获得候选样本集合,然后通过余弦窗来减少由于循环移位造成的边缘噪声,形成的循环矩阵如下:
其中,第一行是经过余弦窗处理的基样本向量转置;
步骤3.1.2:跟踪问题的时域-空域转化:决策函数公式表示为f(z)=wTz,其中z是候选样本,即下一帧图像中车辆所有的可能位置,w是相关滤波器,将方便求解的岭回归函数应用到滤波器的训练过程中,故w的计算公式为其中λ为控制过度拟合的正则化因子,N为训练样本数量,xi为训练样本,yi为训练样本类别值,对于循环样本中xi赋予满足高斯分布的样本标签yi,根据目标对象距离的远近来赋值[0-1],越接近目标对象则标签值yi越接近于1,否则接近于0,公式表示为其中,μ、σ分别为距离目标对象距离的均值和方差;
步骤3.1.3:在时域下的w求解设计到线性方程的高维求解,计算复杂度,将其转换到空域内计算,其计算公式为其中为xi的傅里叶变换向量,为向量的复共轭,为yi的傅里叶变换值,⊙表示代表向量对应元素相乘,在求解w的频域解后通过傅里叶的逆变换重新得到时域解w;
步骤3.1.4:跟踪目标位置预测;引入核技巧将低维空间的X候选样本映射到高维空间进行分类,故在空域下决策函数的公式表示为其中kxz是目标样本X和候选样本Z的核相关性,为优化变量矩阵,为kxz的傅里叶变换值;将频域计算的f(z)进行傅里叶逆变换,得到时域置信度,在置信度图像中最大置信度即最大响应值,即可得到Q帧中N个车辆在第Q+1帧中的响应值,将前五名响应值保存到样本序列CQ+1={c1,c2,…,ca,…,cN}中,并将各车辆的最大响应值对应的图像区域添加到预测区域集合KQ+1。
所述步骤3.5还包括如下步骤:
步骤3.5.1:候选框预测:结合视频监控下的车辆特征设计一套车辆检测专属的anchor的窗口尺寸,即采用定制的五种长宽比和三种缩放比例的anchor,对预测框集合K′Q+1作为搜索区域,采用多尺度特征图方法进行候选框预测,得到N个车辆的候选框集合PQ+1;
步骤3.5.2:多目标车辆区分,得到帧数Q+1的N个车辆的目标框集合SQ+1;采用非极大值抑制的方法对候选框集合内的所有候选框进行处理,从所有候选框中得到当前帧图像中所有车辆的唯一边界框;
步骤3.5.3:输出目标框集合SQ+1,SQ+1中每个车辆用唯一的边界框表示;该边界框由具有6维的向量表示,即(tx,ty,tw,th,tcon,ttra),其中ttra的计算公式为BBtra表示各车辆通过KCF跟踪算法得到的预测区域集合KQ+1对应的各边界框;
步骤3.5.4:改进的YOLO v3算法中的损失函数计算:损失函数的公式为losstra=ttra·(lossxy+lossnw+losscon+lossncon),其中,lossxy为边界框左上角坐标的损失量,lossnw为边界框宽和高的损失量,losscon为边界框包含车辆目标的置信度损失量,lossncon为边界框不包含车辆目标的置信度损失量。
采用上述技术方案所产生的有益效果在于:本发明提供的一种基于视频跟踪的多目标车辆轨迹识别方法,本发明提供的一种基于视频跟踪的多目标车辆轨迹识别方法,本发明采用改进的YOLO v3算法,在连续跟踪过程中缩减了原YOLO v3算法中搜索区域的大小,将全帧检测和局部检测联合使用进一步加快了车辆检测的速度,克服了深度学习模型检测速度慢的缺点,因此本发明具有很好的实时性;在KCF跟踪算法中每一帧的基样本图像均是经过改进的YOLO v3算法检测的精确图像,使模板在视频序列随时间变化的过程中始终与动态目标保持高度的一致性,克服模板更新后模板不准确的问题,保证了在长期跟踪过程中模板不失真,因此本发明在长期跟踪过程中具有很好的稳定性;本发明利用改进的YOLO v3算法具有多尺度下特征检测的特点,克服了车辆目标在动态运动过程中与摄像头距离不同而产生尺寸变化造成的检测不准确和跟踪不稳定问题,实现了车辆目标的准确动态跟踪;本发明提供的轨迹跟踪方法实现了多目标车辆的跟踪,为每个车辆目标配置一个轨迹集,与实际场景应用更加吻合,对跟踪目标的识别、理解和分析具有重要意义。
附图说明
图1为本发明实施例提供的基于视频跟踪的多目标车辆轨迹识别方法流程图;
图2为本发明实施例提供的YOLO v3算法流程图;
图3为本发明实施例提供的改进的YOLO v3算法流程图;
图4为本发明实施例提供的确定搜索区域的前后帧比较示意图,其中,(a)为全帧检测确定搜索区域时的示意图,(b)为跟踪算法确定搜索区域时的示意图;
图5为本发明实施例提供的多目标车辆轨迹识别效果图;
具体实施方式
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
如图1所示,本实施例的方法如下所述。
本发明提供一种基于视频跟踪的多目标车辆轨迹识别方法,包括如下步骤:
步骤1:采集监控视频图像,进行跟踪前的准备工作,设置相关参数,所述相关参数包括改进的YOLO v3算法参数初始化、置信度阈值设定;
步骤2:如图2所示,根据视频图像采用YOLO v3算法获取图像中要跟踪的所有车辆目标,将检测到的N个车辆作为跟踪目标,得到N个车辆的第Q帧目标框集合SQ,并以目标车辆的中心点作为轨迹记录点,建立N个车辆的轨迹集L={L1,L2,L3,…,LN},其中LN代表目标车辆N的轨迹集合;如图4(a)所示;
步骤2.1:网格划分;根据YOLO v3算法将输入图像进行网格划分,划分成S×S个网格;
步骤2.2:确定搜索区域;对帧数Q的视频图像进行全帧检测,搜索区域为视频图像中划分的所有网格;
步骤2.3:候选框预测:结合视频监控下的车辆特征设计一套车辆检测专属的anchor的窗口尺寸,即采用定制的五种长宽比(两个横向框、两个纵向框、一个正方形框)和三种缩放比例的anchor,对步骤2.2中的搜索区域采用多尺度特征图方法进行候选框预测,每个网格会产生15个候选框,改进的YOLO v3算法沿用原YOLO v3算法中的多尺度特征图方法,可以有效识别不同尺寸大小的车辆;得到N个车辆的候选框集合PQ;
步骤2.4:多目标车辆区分,得到N个车辆的目标框集合SQ;采用非极大值抑制的方法对候选框集合内的所有候选框进行处理,从所有候选框中得到当前帧图像中所有车辆的唯一边界框;
步骤2.5:输出目标框集合SQ,SQ中每个车辆用唯一的边界框表示;该边界框由具有6维的向量表示,即(tx,ty,tw,th,tcon,ttra),其中tx、ty为边界框的左上点坐标、tw为边界框的长,th为边界框的宽,tcon为该边界框对应的置信度,ttra为边界框在跟踪区域中的置信度,且ttra=0,其中tcon的计算公式为其中,BBpre表示各个车辆对应目标框集合SQ中的边界框,BBtru表示各个车辆的真实边界框,area是对面积的求值;
步骤2.6:根据目标框集合SQ得到所有目标车辆的中心点,并以中心点作为轨迹记录点,建立N个车辆的轨迹集L={L1,L2,L3,…,LN};
步骤3:启动跟踪;根据目标框集合SQ和Q+1帧的视频图像采用改进的YOLO v3算法进行车辆目标检测得到N个车辆Q+1帧的目标框集合SQ+1,重复本步骤,直至将采集的监控视频图像全部检测完毕,输出最终的轨迹集L′;如图3所示;
所述改进的YOLO v3算法为将输入图像划分为网格,利用KCF跟踪算法对当前帧进行处理,预测下一帧中车辆的位置,在下一帧中对预测位置中的网格进行检测,不再对所有网格进行检测;设定设计车辆检测专-属的anchor的窗口尺寸和损失函数,然后采用YOLOv3算法获取目标框集合,得到目标车辆的轨迹集;具体步骤如下:
步骤3.1:基于第Q帧图像中N个车辆的目标框集合SQ,利用KCF跟踪方法计算在Q+1帧中原Q帧中N个车辆的响应值,并将Q+1帧中每个车辆对应的响应值大的前五名保存到样本序列CQ+1={c1,c2,…,ca,…,cN}中,其中代表第a辆车的响应值集合,并将各车辆的最大响应值对应的图像区域添加到预测区域集合KQ+1;如图4(b)所示;
在实施本方法时对KCF跟踪模型中的相关参数进行了更新;
步骤3.1.1:获取候选样本集合:每次跟踪的基样本图像均由步骤2中检测出的多目标车辆的初始化状态确定,所述多目标车辆的初始化状态即指图像中车辆的位置,通过循环移位矩阵X完成密集采样以获得候选样本集合,然后通过余弦窗来减少由于循环移位造成的边缘噪声,形成的循环矩阵如下:
其中,第一行是经过余弦窗处理的基样本向量转置;
步骤3.1.2:跟踪问题的时域-空域转化:决策函数公式表示为f(z)=wTz,其中z是候选样本,即下一帧图像中车辆所有的可能位置,w是相关滤波器,将方便求解的岭回归函数应用到滤波器的训练过程中,故w的计算公式为其中λ为控制过度拟合的正则化因子,N为训练样本数量,xi为训练样本,yi为训练样本类别值,对于循环样本中xi赋予满足高斯分布的样本标签yi,根据目标对象距离的远近来赋值[0-1],越接近目标对象则标签值yi越接近于1,否则接近于0,公式表示为其中,μ、σ分别为距离目标对象距离的均值和方差;
步骤3.1.3:在时域下的w求解设计到线性方程的高维求解,计算复杂度,将其转换到空域内计算,其计算公式为其中为xi的傅里叶变换向量,为向量的复共轭,为yi的傅里叶变换值,⊙表示代表向量对应元素相乘,在求解w的频域解后通过傅里叶的逆变换重新得到时域解w;
步骤3.1.4:跟踪目标位置预测;引入核技巧将低维空间的X候选样本映射到高维空间进行分类,故在空域下决策函数的公式表示为其中kxz是目标样本X和候选样本Z的核相关性,为优化变量矩阵,为kxz的傅里叶变换值;将频域计算的f(z)进行傅里叶逆变换,得到时域置信度,在置信度图像中最大置信度即最大响应值,即可得到Q帧中N个车辆在第Q+1帧中的响应值,将前五名响应值保存到样本序列CQ+1={c1,c2,…,ca,…,cN}中,并将各车辆的最大响应值对应的图像区域添加到预测区域集合KQ+1;
步骤3.2:置信度判断:分别计算当前帧中预测区域集合KQ+1与前一帧中目标框集合SQ各车辆预测框的IOU值,并将其作为置信度,可得置信度集合M=[m1,m2…mN],计算公式为ma的值范围为[0,1],其中,area表示各预测框的面积,sa代表第a辆车在Q帧时的目标框,ka代表第a辆车在Q+1帧时的预测区域,分子为两个预测框的交集,分母为两个预测框的并集;对置信度集合M中的元素分别判断其是否大于置信度阈值,若是,则认为是有效跟踪,则将预测区域储存至预测框集合K′Q+1中,执行步骤3.4;若否,则认为是无效跟踪,则获取所有无效跟踪的目标车辆以及目标车辆相对应的响应值集合,分别将响应值集合内的响应值依次作为当前帧的最大响应值,即预测区域,求出预测区域与前一帧中目标框集合中对应车辆目标框的IOU值,再进行置信度判断,若为有效跟踪,则将该预测区域储存至预测框集合K′Q+1中,执行步骤3.3;若目标车辆均为无效检测则认为车辆消失在监控视频中,则执行步骤3.4;
步骤3.3:判断预测框集合K′Q+1内的预测框数量是否为N个,若否,则删除预测框集合K′Q+1,执行步骤3.4,若是,则执行步骤3.5;
步骤3.4:根据Q+1帧的视频图像采用YOLO v3算法获取图像中要跟踪的N个目标车辆,得到N个车辆的第Q+1帧目标框集合SQ+1,执行步骤3.6;
步骤3.5:将预测框集合K′Q+1作为搜索区域,采用YOLO v3算法进行目标车辆检测,得到第Q+1帧的目标框集合SQ+1;
步骤3.5.1:候选框预测:结合视频监控下的车辆特征设计一套车辆检测专属的anchor的窗口尺寸,即采用定制的五种长宽比(两个横向框、两个纵向框、一个正方形框)和三种缩放比例的anchor,对预测框集合K′Q+1作为搜索区域,采用多尺度特征图方法进行候选框预测,得到N个车辆的候选框集合PQ+1;改进的YOLO v3算法沿用原YOLO v3算法中的多尺度特征图方法,可以有效识别不同尺寸大小的车辆;
步骤3.5.2:多目标车辆区分,得到帧数Q+1的N个车辆的目标框集合SQ+1;采用非极大值抑制的方法对候选框集合内的所有候选框进行处理,从所有候选框中得到当前帧图像中所有车辆的唯一边界框;
步骤3.5.3:输出目标框集合SQ+1,SQ+1中每个车辆用唯一的边界框表示;该边界框由具有6维的向量表示,即(tx,ty,tw,th,tcon,ttra),其中ttra的计算公式为BBtra表示各车辆通过KCF跟踪算法得到的预测区域集合KQ+1对应的各边界框;
步骤3.5.4:YOLO v3算法中的损失函数计算:在计算损失函数时本发明忽略首帧检测时的损失量,只考虑由跟踪算法得到搜索区域计算而来的损失量,故改进的YOLO v3算法中YOLO v3算法中的损失函数的公式为losstra=ttra·(lossxy+lossnw+losscon+lossncon),其中,lossxy为边界框左上角坐标的损失量,lossnw为边界框宽和高的损失量,losscon为边界框包含车辆目标的置信度损失量,lossncon为边界框不包含车辆目标的置信度损失量;
步骤3.6:轨迹获取与记录:计算得到的当前帧中所有车辆的中心点,并将各车辆的最新位置更新到轨迹集L={L1,L2,L3,…,LN}中;
步骤3.7:令Q=Q+1,执行步骤3.1;直至将采集的监控视频图像全部检测完毕,输出最终的轨迹集L′;如图5所示;
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明权利要求所限定的范围。
一种基于视频跟踪的多目标车辆轨迹识别方法
展开 >
























































 400-4929-0909
400-4929-0909
 contact@catarc.com.cn
contact@catarc.com.cn

